


推荐 3 个 yyds 的开源项目!
大家好,今天咱们继续聊聊科技圈发生的那些事儿。
一、GS Quant
GS Quant是一个用于量化金融的 Python 工具包,GS 其实就是 Goldman Sachs 高盛集团的缩写。
GS Quant 的功能主要涵盖了以下几个方面:
内置很多金融衍生品定价模型,涵盖多个资产类别
提供了公司内部及市场的数据接口,便于监测
提供风险管理、风险评估工具
构造交易逻辑
所以,无论是在量化交易的策略定制,企业内部管理投资风险,又或者是专业教学任务,GS Quant都可以有很不错的表现。毕竟,这么大的公司自己做的,能拿出来开源的,质量应该还是不错的。
项目可以,以Python包的形式直接使用,直接使用以下命令安装后导入即可。
pip install gs-quant
这里我们可以看看官方的使用示例,使用GS Quant生成一个随机时间序列并计算 1 个月(22 天)滚动已实现波动率:
import gs_quant.timeseries as ts
from gs_quant.timeseries import Window
x = ts.generate_series(1000) # Generate random timeseries with 1000 observations
vol = ts.volatility(x, Window(22, 0)) # Compute realized volatility using a window of 22 and a ramp up value of 0
vol.tail() # Show last few values
这是运行这段代码之后的结果:
Out[1]:
2021-12-20 12.898025
2021-12-21 12.927230
2021-12-22 12.929520
2021-12-23 13.987033
2021-12-24 14.048165
dtype: float64
更多的API和使用方法可以查看官方文档。对量化金融感兴趣的小伙伴可以自行体验一下这个工具。
项目地址:
https://github.com/goldmansachs/gs-quant
二、GraphRAG
最近几天,微软团队开源了GraphRAG,这是一种基于图(Graph)的检索增强生成方法。
先说说RAG吧,检索增强生成,相当于是从一个给定好的知识库中进行检索,接入LLM模型,让模型生成准确且符合上下文的答案,减少幻觉,根据特定的知识库进行符合知识库内容的回答。如果和模型微调进行比较,通俗点来说,RAG是给模型一本《答案全解》让它自己查,微调是给模型开辅导班补习。不过,传统RAG有一些待解决的问题,比如推理能力不足,答案不完整,准确性不足等。
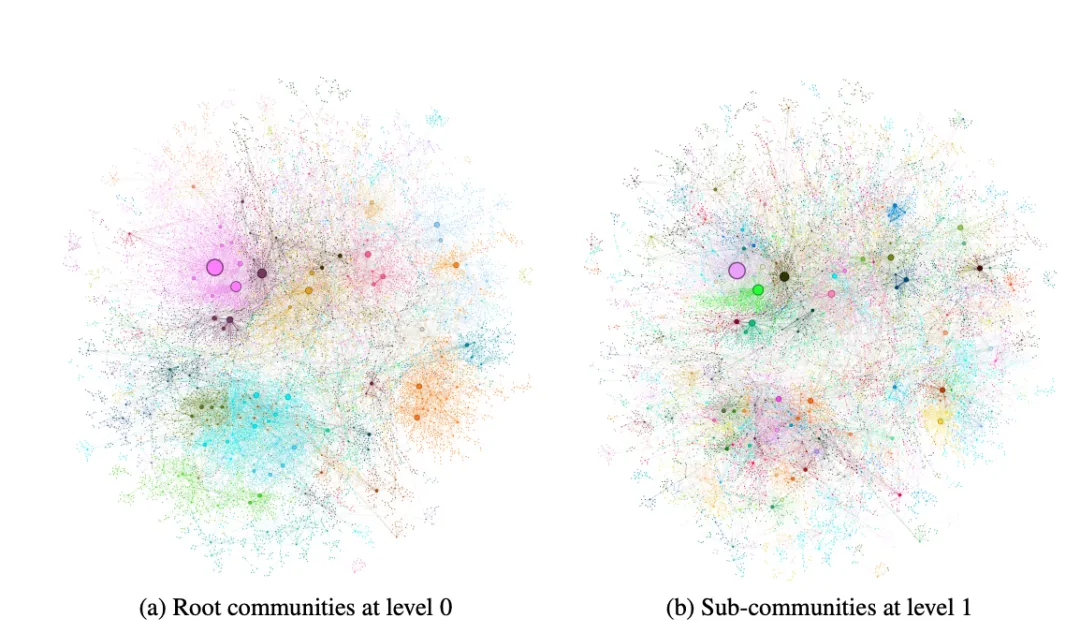
而 GraphRAG 的实现流程大致如下,首先将输入文本转化为文本块,让 LLM 提取知识图谱,将知识图谱聚类,基于关键词实现子图遍历。
我们直接来看看 GraphRAG 的实战测试吧。测试基于俄乌双方关于暴力事件的上千份新闻报道,文件内容比较多,而且内容之间关系复杂,无法直接放入LLM的上下文中,RAG方法是此时的最优解。团队首先测试了第一个问题:Novorossiya 是什么?

可以看到无论是 Baseline RAG 还是 GraphRAG 表现都很好,因为这种查询确实是基线RAG擅长的部分,查就完了。
但如果把问题换成:Novorossiya 做了什么?
Baseline RAG 根本没法给出答案,它的源文件中没有任何东西提到这个关键词。而 GraphRAG 让 LLM 建立了知识图谱,分析实体之间的关系,生成了很不错的答案。GraphRAG 极大的提升了 RAG 的检索能力,在捕获上下文的这个过程中可以填充更多具有相关性的内容,从而让生成的答案更具准确性。
不过有一个无法避免的问题:所有的性能改进技术,都会导致 token 的使用和推理的时间增加。但这并不影响 GraphRAG 的优秀,让我们一起期待一下GraphRAG的进一步发展吧!
项目地址:
https://github.com/microsoft/graphrag
三、FunAudioLLM
在 B 站的新视频中,我们介绍了阿里新开源的 FunAudioLLM 项目。
之前很多读者留言说到,如果只有短短几秒的微信语音,如何才能模仿他们的声音?在当时,各种项目不是效果不好,就是无法根据这么短的输入音频进行声音模仿。不过现在,依靠 FunAudioLLM,我们终于可以实现了!
只需三秒的输入音频,提供输入文本,FunAudioLLM 可以生成具有相同音色的音频。更让人惊喜的是,项目支持跨语言语音翻译!比如你只给出了一段中文的语音,项目可以帮你生成相同音色下,粤语、日语、英语等不同语种的声音,想象一下,哪怕自己日语的五十音图都还没有认全,借助 FunAudioLLM 的 CosyVoice,你甚至可以听到自己的声音说着流利的日语!
而 FunAudioLLM 的功能远不止如此。如果我们将一本书输入给大模型,让大模型尝试理解书中各个人物的性格、情感,模拟出他们的情绪特点和音色,通过 CosyVoice 的语音合成功能,你可以得到一段旁白,其中不同的人物有不同的音色与情绪。

项目的高级功能还有很多。不知道大家有没有看过一本网络小说《十日终焉》,小说里的角色“青龙”具有分辨不出是男是女的神奇音色,我根本无法想象这个声音到底是什么样的。通过 FunAudioLLM,你可以输入两个不同音色的输入音频,项目可以合成两个音色,创造出一个可能真的从未存在的声音!甚至,你可以调整偏好,让生成出的音色更贴近某一个音源。
此外,先前介绍过的 ChatTTS 可以通过打标签的形式让生成出带情绪起伏的音频,比如大笑、悲伤、强调,FunAudioLLM同样能做到。还有给识别到的语音加标点符号,通过识别语音中的音乐查询到音乐的名字,都是非常实用的功能。
项目地址: